Crawler included!
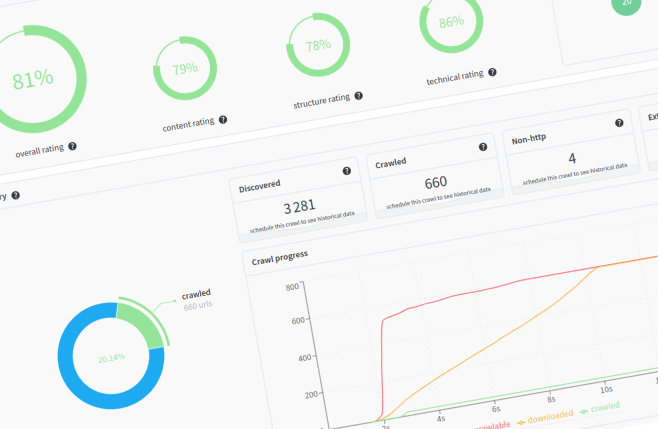
redirection.io comes with a full featured crawler opened to paid projects. Our crawler is fast, reliable and allows to easily spot quality, performance, SEO or content issues.
More than 60 indicators are collected for each crawled page, allowing to get detailed insights on a website quality, as long as a general overview of the website rating.
Discover the issues in your website, and fix those directly, in a matter of seconds, using our SEO rules engine!